The race among LLM companies to produce the best-performing language models is more intense than ever. Despite their transformative impact on various industries, LLMs still grapple with issues of bias and the need to deliver consistently accurate results. A recent publication by Moaryeri et al. sheds light on this challenge by evaluating the accuracy of 20 different LLMs in recalling 11 country-specific statistics, such as population and GDP, sourced from the World Bank.
In a previous post I discussed the overall average bias of all LLMs. In this post, we will delve into the specific performance of each LLM as per the study parameters.
Top Performers
The study’s findings reveal that models like OpenAI ChatGPT, Google Gemini, and Cohere + RAG are consistently among the top performers (note: no Anthropic models were used in the study). The metric used to evaluate these models is the Absolute Relative Error (ARE), defined as |a - b| / max(a, b), where a is the LLM-generated value and b is the ground truth value from World Bank data.
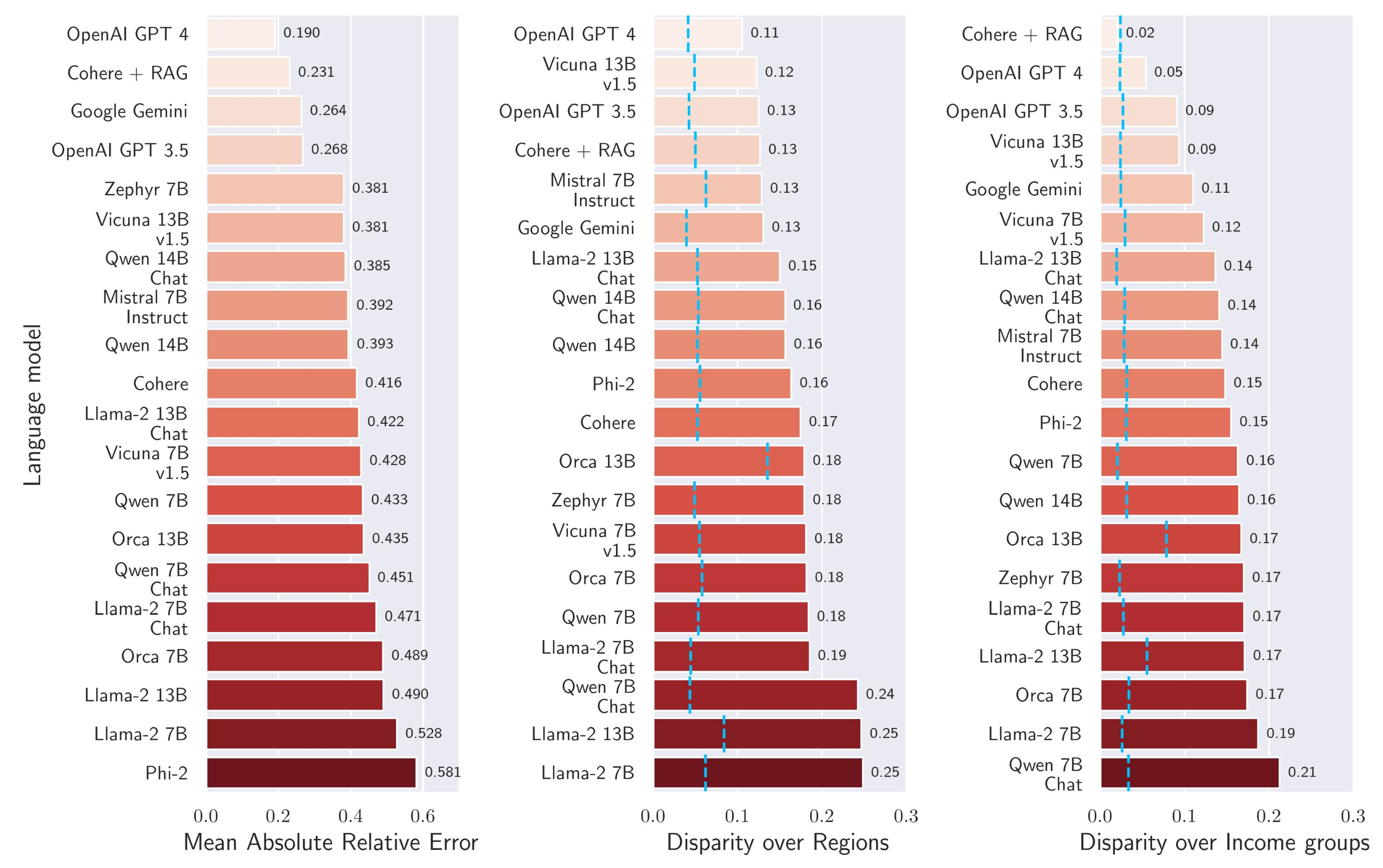
The Impact of RAG
Retrieval-Augmented Generation (RAG) enhances LLM performance by incorporating relevant documents or information to provide specific or up-to-date responses. This approach can significantly improve accuracy and reduce hallucinations. While many models may use some form of RAG, Cohere explicitly markets its in-house RAG framework and this study uses the Cohere model both with and without the RAG component — allowing for a direct comparison.
We can see that the addition of RAG elevates Cohere from a middling performer to the second-best overall model. Notably, the Cohere + RAG model exhibits no bias relative to country income group, as shown by the minimal income disparity being the same as the expected disparity given randomized country groupings.
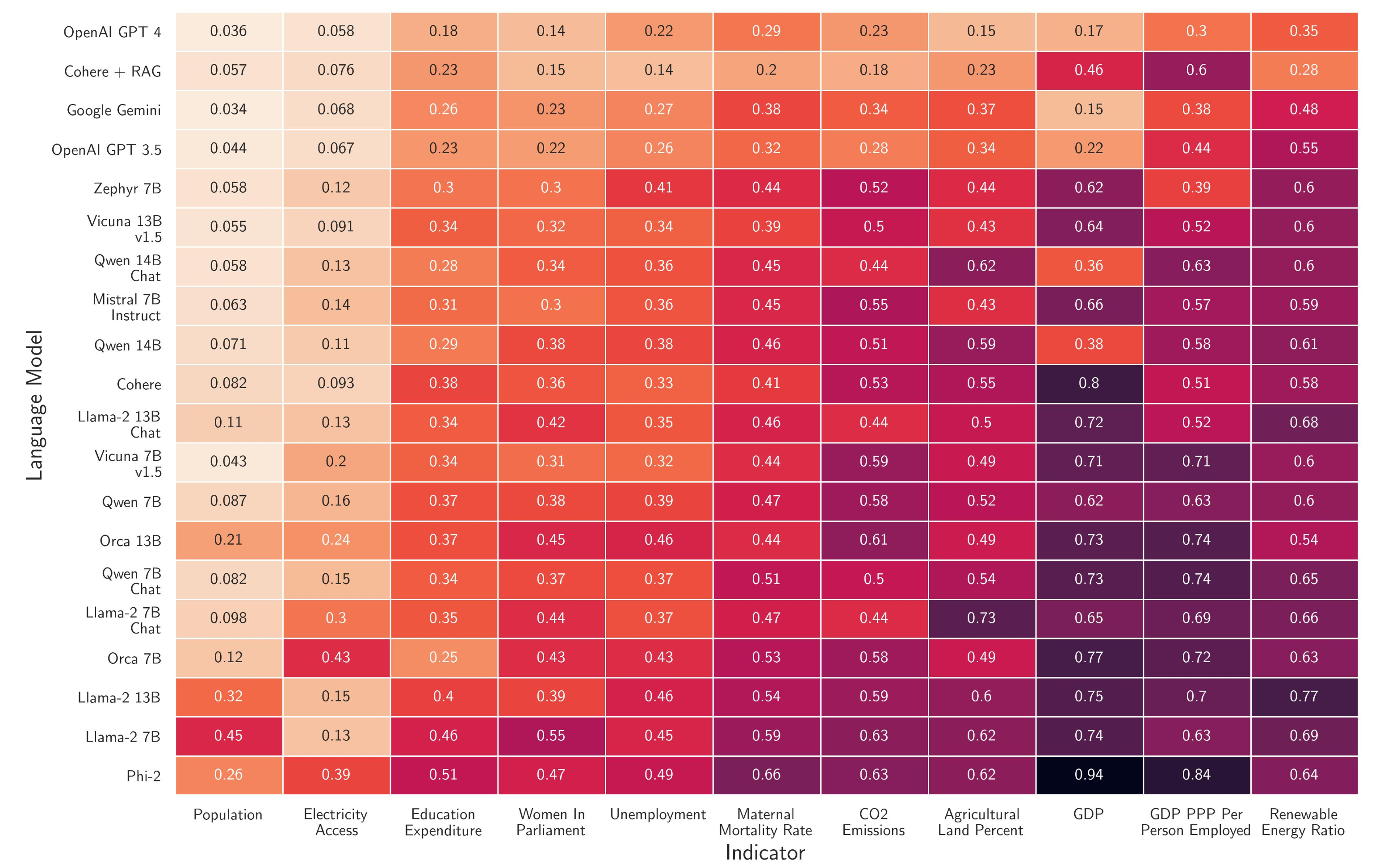
Statistic-Specific Performance
The quantitative analysis reveals that fact recall performance varies significantly depending on the specific statistic. Most models perform relatively well with population metrics, likely due to the stability of population figures year-to-year.
Looking Ahead
It will be fascinating to observe how benchmarks like this evolve over time and reflect improvements in LLM performance. One of the most intriguing potential implications is whether current model frameworks — whether utilizing RAG or new model architectures — can eventually exhibit no geographic or income-based bias when evaluated with robust data sources.
If future models demonstrate no bias in studies like this, it would strongly suggest that enhancing data diversity, quality, and robustness can lead to unbiased responses for a broader range of prompts. This would mark a significant advancement in developing equitable AI systems.